您现在的位置是: 首页 > MySQL MySQL
MYSQL取随机数据
 冬寂
2020-08-05 23:23:08
【MySQL】
4458人已围观
冬寂
2020-08-05 23:23:08
【MySQL】
4458人已围观
一 、 被MYSQL警告的一种写法
> SELECT * FROM table order by rand() limit 10;
(如果你的数据永远不会超过10000条,这是最简单的方式,数据量大就尽早绕道)
缺点:效率极低
二 、 连续ID方式
> SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`))+(SELECT MIN(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id ORDER BY t1.id LIMIT 10;
每次取的数据起始位置都是随机的,但结果ID连续
优点:效率高
缺点:ID连续
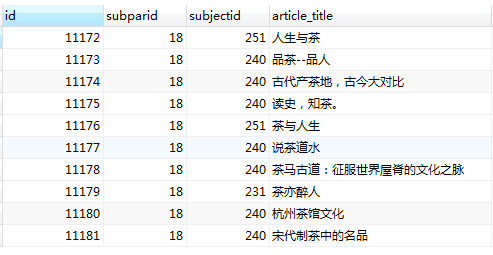
三 、 ID不连续,随机方式,效率高
> SELECT * FROM table WHERE id >= ((SELECT MAX(id) FROM table) - (SELECT MIN(id) FROM `table`)) * RAND() + (SELECT MIN(id) FROM `table`) limit 10;
优点:效率高,ID不连续,执行效率高
四 、 但是你可能会发现,以上都有一定的好或者难以实行的缺陷
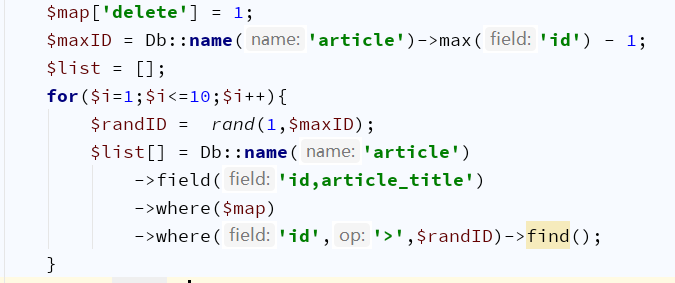
PHP傻瓜式
最后傻瓜式思路,你可能觉得太low,但是这样做没问题的
取数据库最小ID与最大ID,生成一个随机数 r
然后 where 条件中 id>r 只取一行
取10条数据为例,循环10次
缺点:执行太多次查询,本能告诉我们这行为不友好,确实不友好,效率相对低
优点:不论你有多大的数据量,效率都不会被拉很低,相对会地一点,但绝对在接受范围内
100万数据 小于0.5秒
执行时间在小数据量和大数据量波动很低.
五 、 有个思路
将所有ID放到缓存,比如redis,数据增加减少都去操作redis,
直接取redis随机个ID, where in去取数据
缺点:稳定性不高,另外 where in效率不高
推荐第三种方式
也推荐第四种方式
有的代码,想法”LOW”,写法”LOW”,但耐不住实用
上一篇: mysql重建主键ID
下一篇: 没有了!