您现在的位置是: 首页 > MySQL MySQL
NOSQL数据库之 - Redis(1)
 冬寂
2020-08-27 13:52:22
【MySQL】
2551人已围观
冬寂
2020-08-27 13:52:22
【MySQL】
2551人已围观
一、NOSQL
1、简介
NoSQL ,(Not Only SQL),泛指非关系型数据库。
特点:
NoSQL 通常是以key-value形式存储,
不支持SQL语句,
没有表结构
2、优缺点:
优点:
- 高并发读写的性能
- 大数据量的扩展(分布式存储)
- 配置简单
- 灵活、高效的操作与数据模型
- 低廉的成本
不足之处:
- 没有统一的标准
- 没有正式的官方支持
- 各种产品还不算成熟
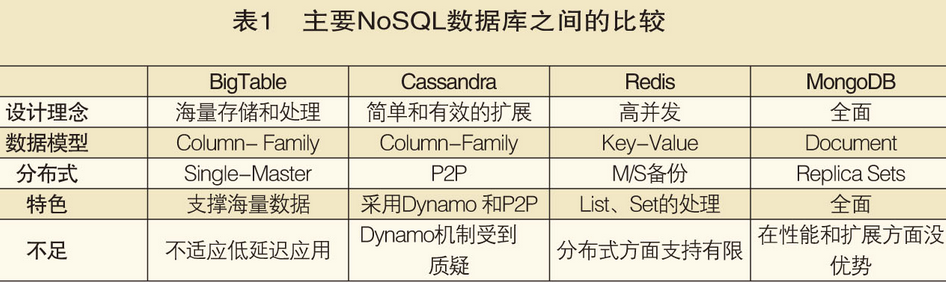
3、常见nosql产品

二、redis介绍
1、概述
- (1)Redis是Remote Dictionary Server(远程数据服务)的缩写.
- 由意大利人antirez(Salvatore Sanfilippo)开发的一款内存高速缓存数据库
- (2)该软件使用C语言编写,它的数据模型为key-value
- (3)它支持存储的value类型很多,包括string(字符串)、hash(哈希)、list(链表)、set(集合)、Zset(有序集合)。
- (4)为了保证效率数据都是缓存在内存中,它也可以周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
2、特点
1)高速读取数据(in-memory)
2)减轻数据库负担
3)有集合计算功能(优于普通数据库和同类别产品)
4)多种数据结构支持
3、适合场合及其优势
- 1)[Sort Set]排行榜应用,取top n操作,例如sina微博热门话题
- 2)[List]获得最新N个数据 或 某个分类的最新数据
- 3)计数器应用
- 4)[Set]sns(social network site)获得共同好友
- 5)[Set]防攻击系统(ip判断)等等
4、与memcache比较说明
redis与memcache比较
- (1)数据类型:memcache支持的数据类型就是字符串,redis支持的数据类型有字符串,哈希,链表,集合,有序集合。
- (2)持久化:memcache数据是存储到内存里面,一旦断电,或重启,则数据丢失。redis数据也是存储到内存里面的,但是可以持久化,周期性的把数据给保存到硬盘里面,导致重启,或断电不会丢失数据。
- (3)数据量:memcahce一个键存储的数据最大是1M,而redis的一个键值,存储的最大数据量是1G的数据量。
三、数据类型讲解
1、字符串(string)
string是redis最基本的类型
redis的string可以包含任何数据。包括jpg图片或者序列化的对象。
单个value值最大上限是1G字节, 如果只用string类型,redis就可以被看作加上持久化特性(服务器重启之后,数据不丢失)的memcache
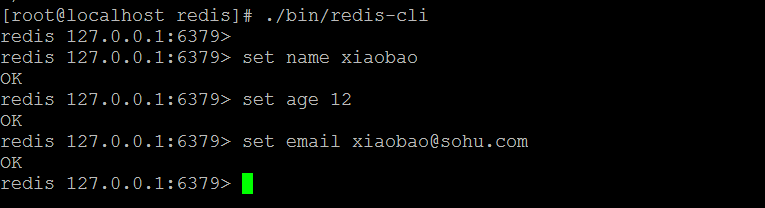
(1)set
- 设置键,值
- 语法:set 键名称 值
- 例如:我们添加一个name=“xiaoqian”的键值对。
- 注意:重新设置则直接覆盖。
(2)get
- 获取key对应的string值,如果key不存在返回 nil,
- 语法:get 键值

(3)incr
- 对key的值做加加操作,并返回新的值,每执行一次值加1,值类型要是数据类型。
- 语法:incr key
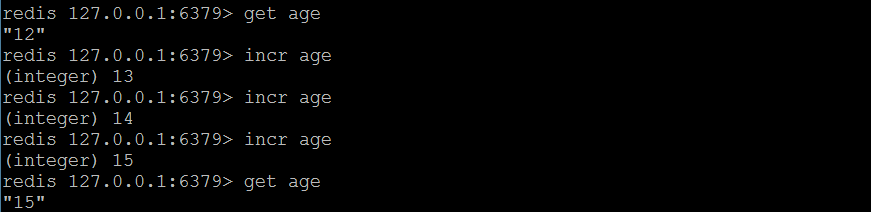
(4)incrby
- 执行加法的命令,可以指定相加的值,

2、hash
hash可以用来存储对应的mysql中一行的数据,类似于关联数组。
(1)hset
- 设置哈希里面的field和vlaue的值。
- 语法:
- hset 哈希的名称(键名称) field value

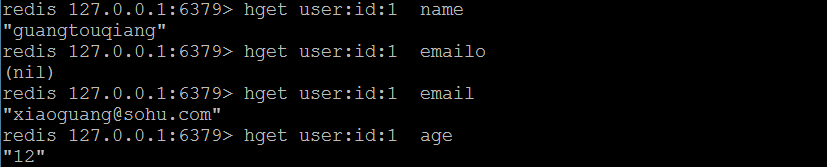
(2)hget
- 获取哈希里面的field的值
语法:hget 哈希的名称(键名称) 指定的field
注意:user
 1 名称里面的:符号,就表示一个普通符号,没有任何含义。
1 名称里面的:符号,就表示一个普通符号,没有任何含义。
(3)hmset
- 一次性设置多个field和value
- 语法: hmset 哈希的名称 field1 value1 field2 value2……

(4)hmget
- 一次性获取 多个field的value
- 语法:hmget 哈希的名称 field1 field2…….

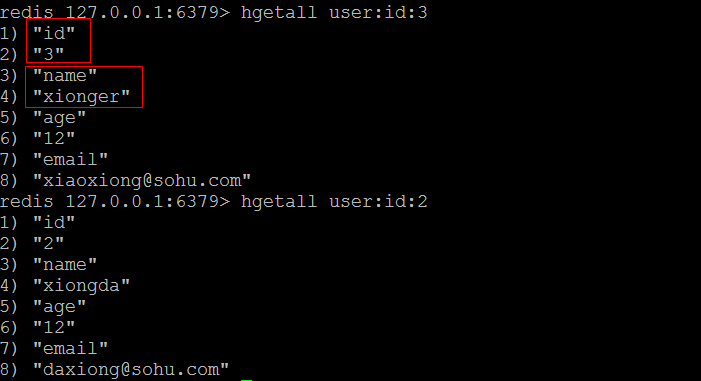
(5)hgetall
- 获取指定哈希中所有的field和value
- 语法:
- hgetall 哈希的名称
3、链表(list)
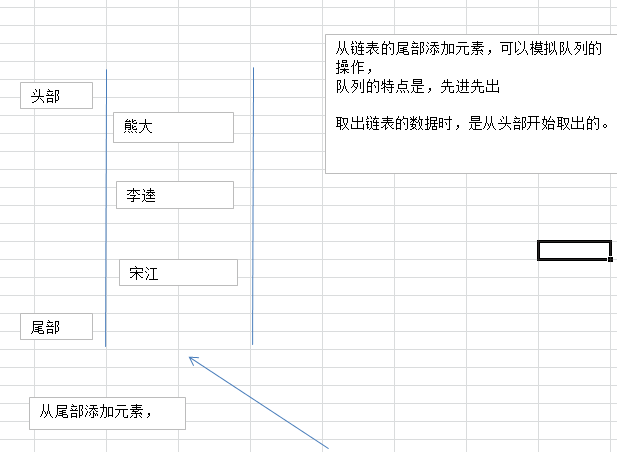
list类型其实就是一个双向链表。通过push,pop操作从链表的头部或者尾部添加删除元素。
这使得list既可以用作栈,也可以用作队列。
上进上出 :栈 ,特点:数据 先进后出
下进上出 :队列,特点:数据 先进先出
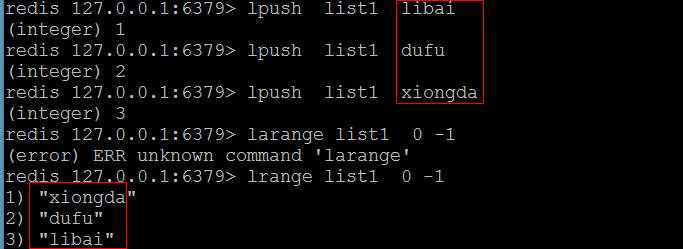
(1)lpush
- 从链表的头部添加元素
- 语法: lpush 链表的名称(键的名称) 元素

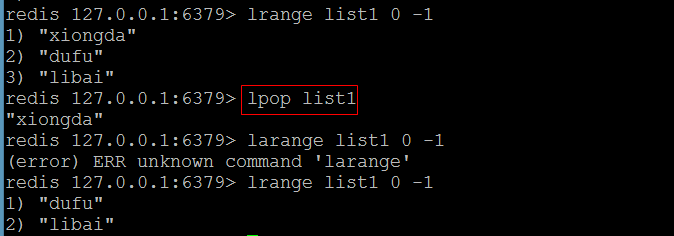
(2)lrange
- 获取链表里面的元素
- 语法:
- lragne 链表的名称 开始下标 结束下标
- 注意:如果开始下标是0结束下标是-1则是返回链表中所有的元素。
- 注意:链表里面的元素是序号的(从0开始数),类似于索引数组。

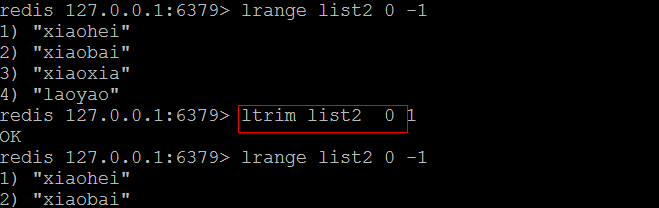
(3)rpush
- 从链表的尾部添加元素
- 语法: rpush 链表的名称(键的名称) 元素

(4)ltrim
- 保留指定范围的元素
- 语法:ltrim 链表的名称 开始下标 结束下标
(5)lpop
- 从链表的头部删除一个元素,返回删除的元素
- 语法:lpop 链表的名称
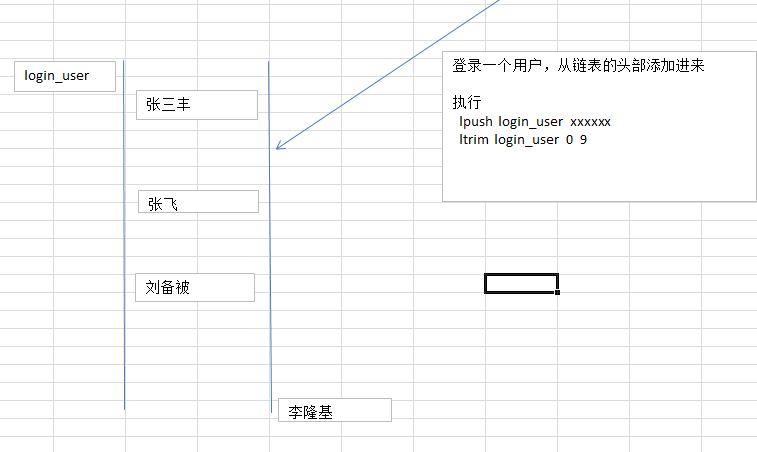
- 比如如下案例:一个网站中,想要获取最新登录的10个用户。
- 使用传统的方法解决,查询用户表,根据登录时间排序,截取前10位。
- 类似于如下sql语句
- select * from user order by login_time desc limit 10;
- 以上sql语句,如果用户数量庞大,则执行效率比较低,可以把登录的用户存储到redis的链表里面,
如果通过list链表实现以上功能,可以在list链表中只保留最新的10个数据,每进来一个新数据就删除一个旧数据。每次就可以从链表中直接获得需要的数据。极大节省各方面资源消耗
4、集合(set)
redis的set是string类型的无序集合。
set元素最大可以包含(2的32次方-1)(整型最大值)个元素。
关于set集合类型除了基本的添加、删除操作,其他有用的操作还包含集合的取并集(union),交集(intersection),差集(difference)。通过这些操作可以很容易的实现sns中的好友推荐功能。
sina公司的好友关注关系就大量使用了set集合类型。
注意:每个集合中的各个元素不能重复。
该类型应用场合:qq好友推荐。
tom朋友圈(与某某是好友):mary jack xiaoming wang5 wang6
linken朋友圈(与某某是好友):yuehan daxiong luce wang5 wang6

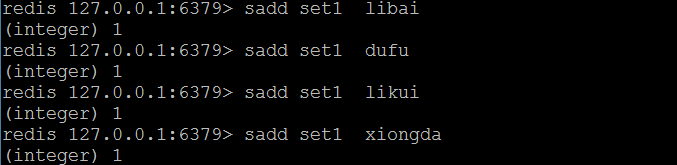
(1)sadd
- 向集合中添加元素
- 语法:
- sadd 集合名(键名) 元素名称
(2)smembers
- 获取集合中的元素
- 语法:
- smembers 集合名

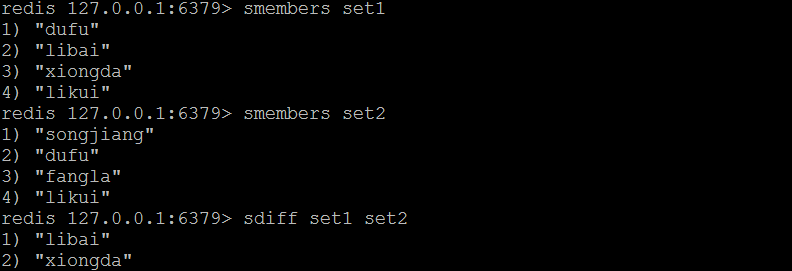
(3)sdiff
- 获取集合中的差集(在集合1中存在,不在集合2中存在的元素)
- 语法:sdiff 集合1 集合2
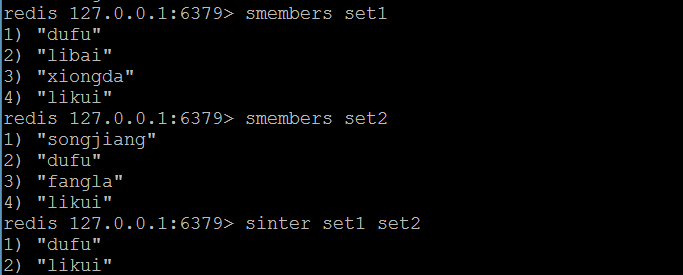
(4)sinter
- 获取交集(在两个集合中都存在的元素)
- 语法:sinter 集合1 集合2
(5)sunion
- 求并集(两个集合合并后,去掉重复的元素)
- 语法:sunion 集合1 集合2

(6)scard
- 获取集合中元素的个数
- 语法:scard 集合名称

5、(有序集合)zset
sorted set是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。操作中的key理解为zset的名字。
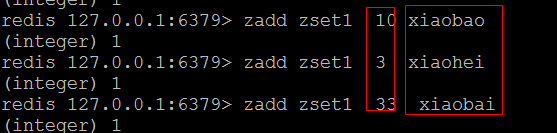
(1)zadd
- 向有序集合中添加元素。如果该元素存在,则更新其顺序。
- 语法:zadd 集合名 序号 内容
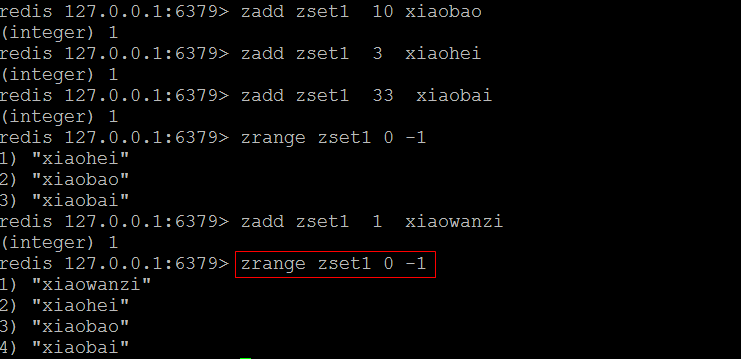
(2)zrange
- (把集合排序后,返回名次[start,stop]的元素
- 默认是升续排列
- Withscores 是把score也打印出来 )
- 按序号升序获取有序集合中的内容,
- 语法:zrange 集合名称 开始下标 结束下标
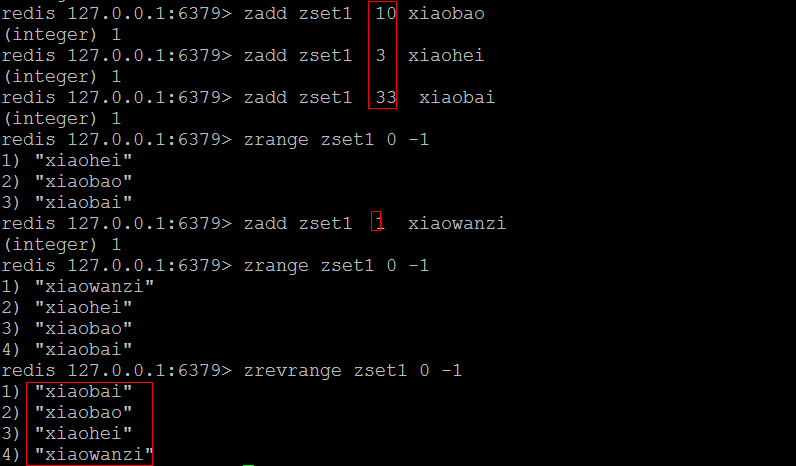
(3)zrevrange
- 按序号降序获取有序集合中的内容。
- 语法:zrevrange 集合名称 开始下标(索引) 结束下标(索引)
上一篇: NOSQL数据库之 - Redis(2)
下一篇: mysql重建主键ID
相关文章
随机图文
-

linux: ln添加软链ln添加软链
ln -s 软链接文件目录【绝对路径】 软链接名字(请在要创建软链接的文件中执行该命令,软链接会创建在该文件中) -

Layui的本地存储方法-Layui.data的基本使用
Layui的本地存储方法-Layui.data的基本使用 -

ThinkPHP6.0 内容导出 Word 案例
ThinkPHP6.0 内容导出 Word 案例 -

韦伯天文望远镜将会改写宇宙历史,如果它能正常工作的话(The Webb Space Telescope Will Rewrite Cosmic History. If It Works.)
韦伯天文望远镜将会改写宇宙历史,如果它能正常工作的话,The Webb Space Telescope Will Rewrite Cosmic History. If It Works.